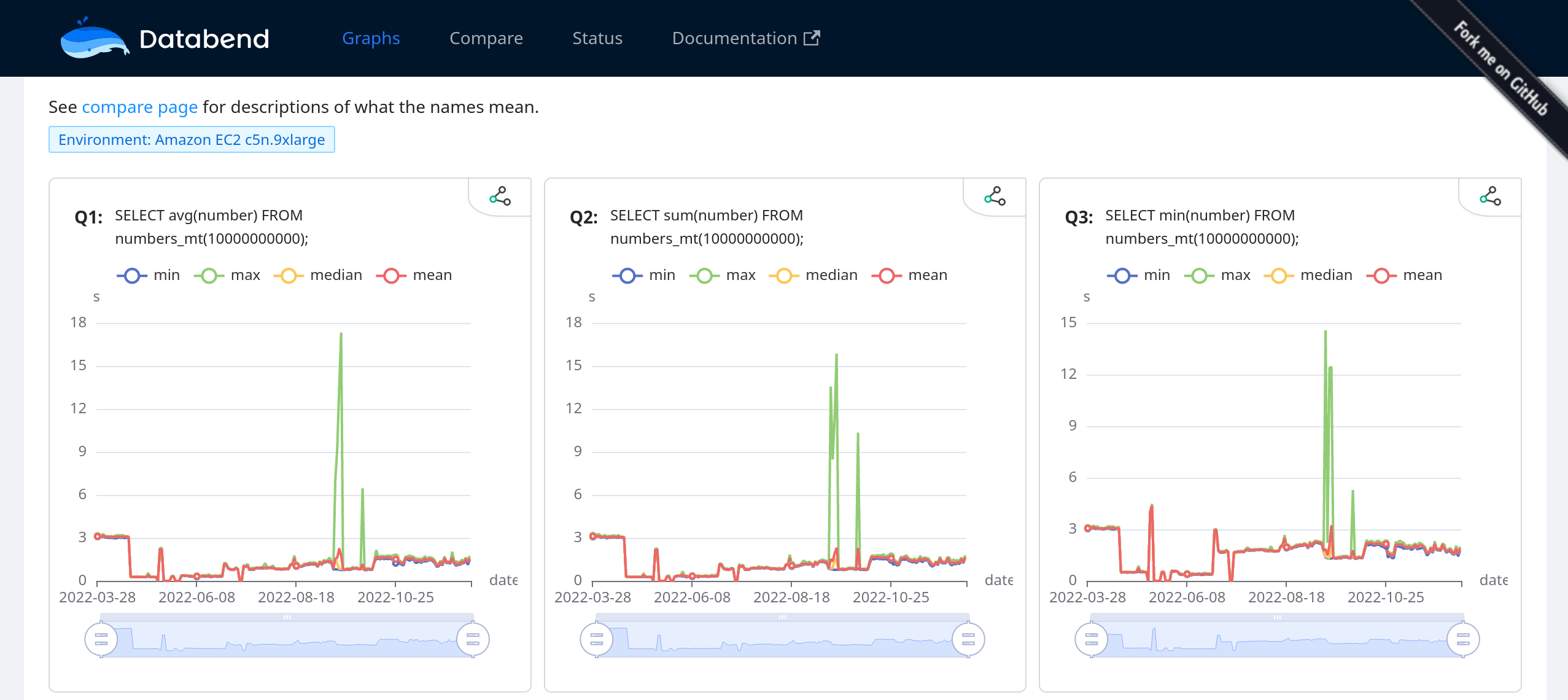
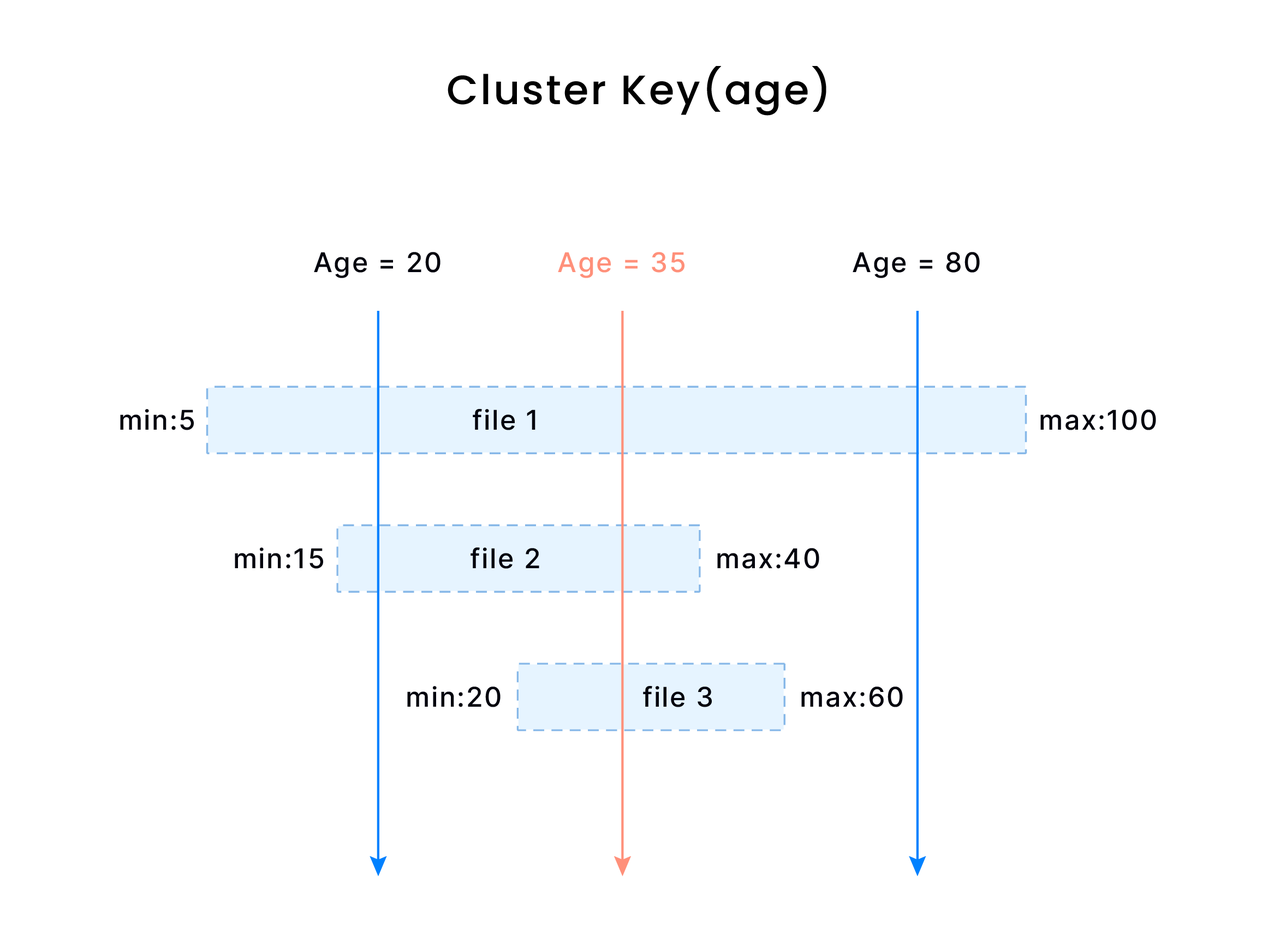
Databend is a modern cloud data warehouse, serving your massive-scale analytics needs at low cost and complexity. Open source alternative to Snowflake. Also available in the cloud: https://app.databend.com .
What's New
Check out what we've done this week to make Databend even better for you.
Accepted RFCs :flight_departure:
- rfc: query result cache (#10014)
Features & Improvements ✨
Planner
- support
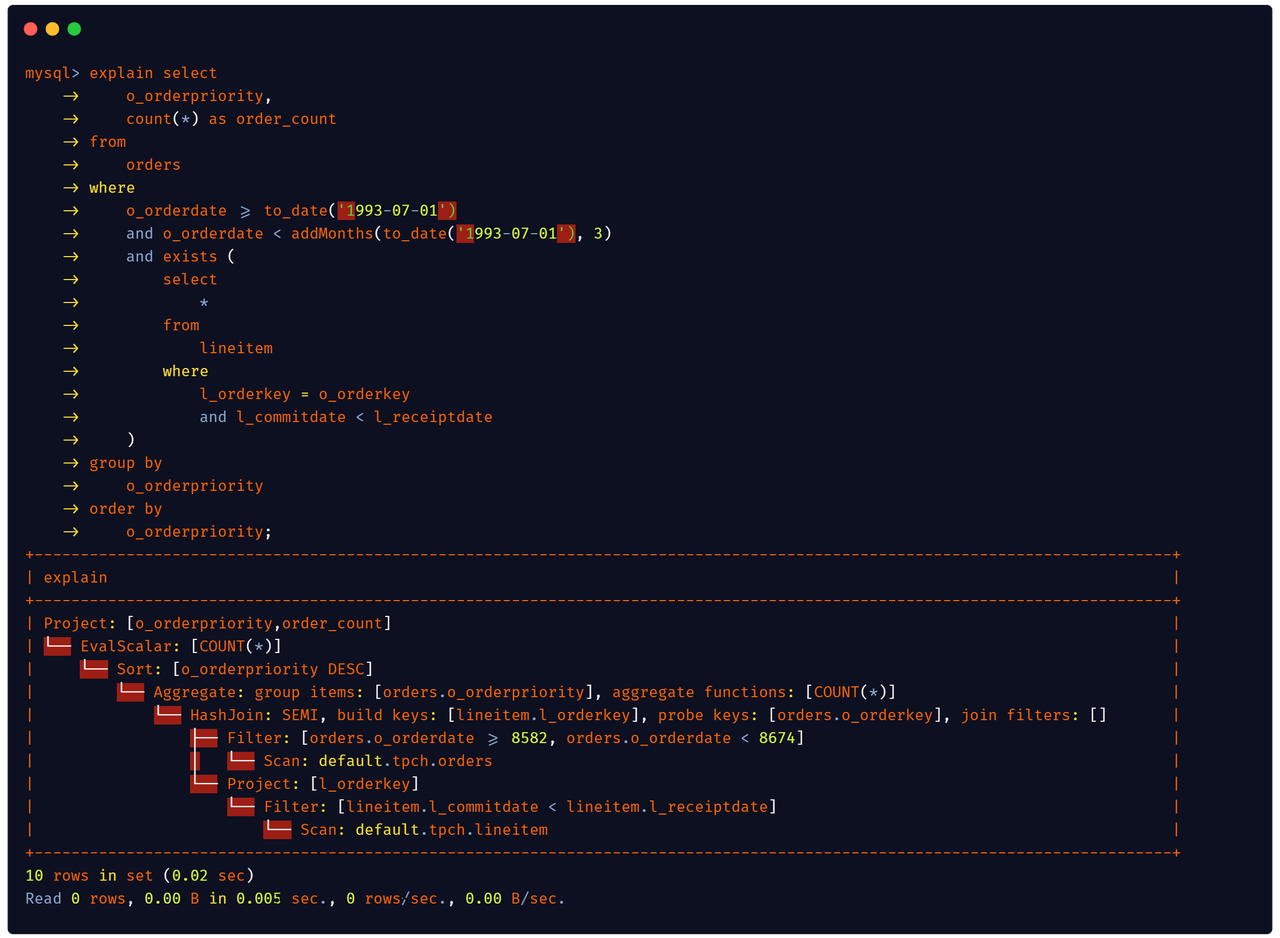
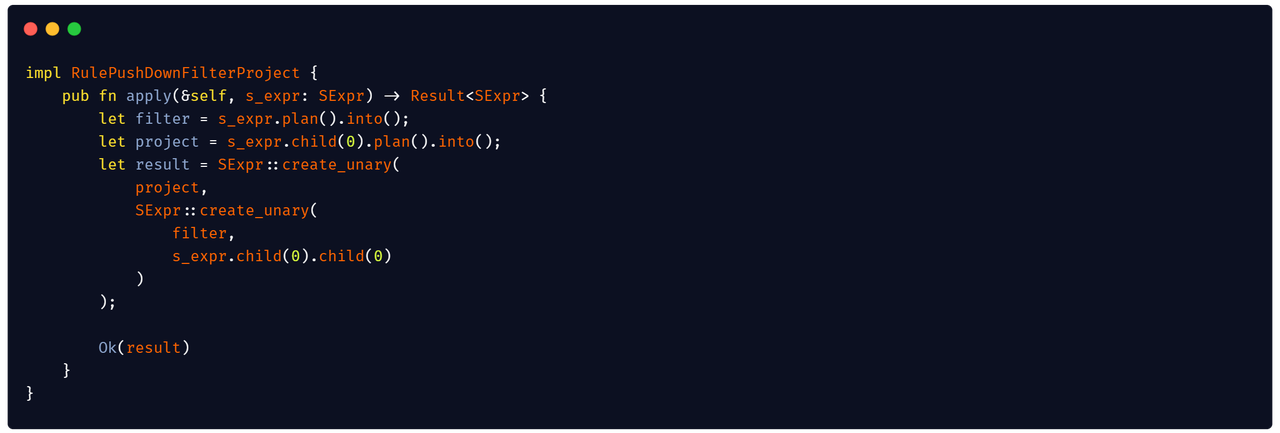
EXPLAIN ANALYZEstatement to profile query execution (#10023) - derive new filter and push down (#10021)
Query
- alter table add/drop column SQL support (#9851)
- new table function
infer_schema(#9936) - add privilege check for select (#9924)
- improve signed numeric keys (#9987)
- support to parse jwt metadata and add multiple identity issuer configuration (#9971)
- support create file format (#10009)
Storage
Expression
- add operation for decimal (#9926)
Functions
Sqllogictest
- add time travel test for alter table (#9939)
Code Refactoring 🎉
Meta
- move application level types such as user/role/storage-config to crate common-meta/app (#9944)
- fix abuse of ErrorCode (#10056)
Query
- use
transform_sort_mergeuse heap to sort blocks (#10047)
Storage
- introduction of FieldIndex and ColumnId types for clear differentiation of use (#10017)
Build/Testing/CI Infra Changes 🔌
Bug Fixes 🔧
Privilege
- add privileges on system.one to PUBLIC by default (#10040)
Catalog
- parts was not distributed evenly (#9951)
Planner
- type assertion failed on subquery (#9937)
- enable outer join to inner join optimization (#9943)
- fix limit pushdown outer join (#10043)
Query
- fix add column update bug (#10037)
Storage
- fix sub-column of added-tuple column return default 0 bug (#9973)
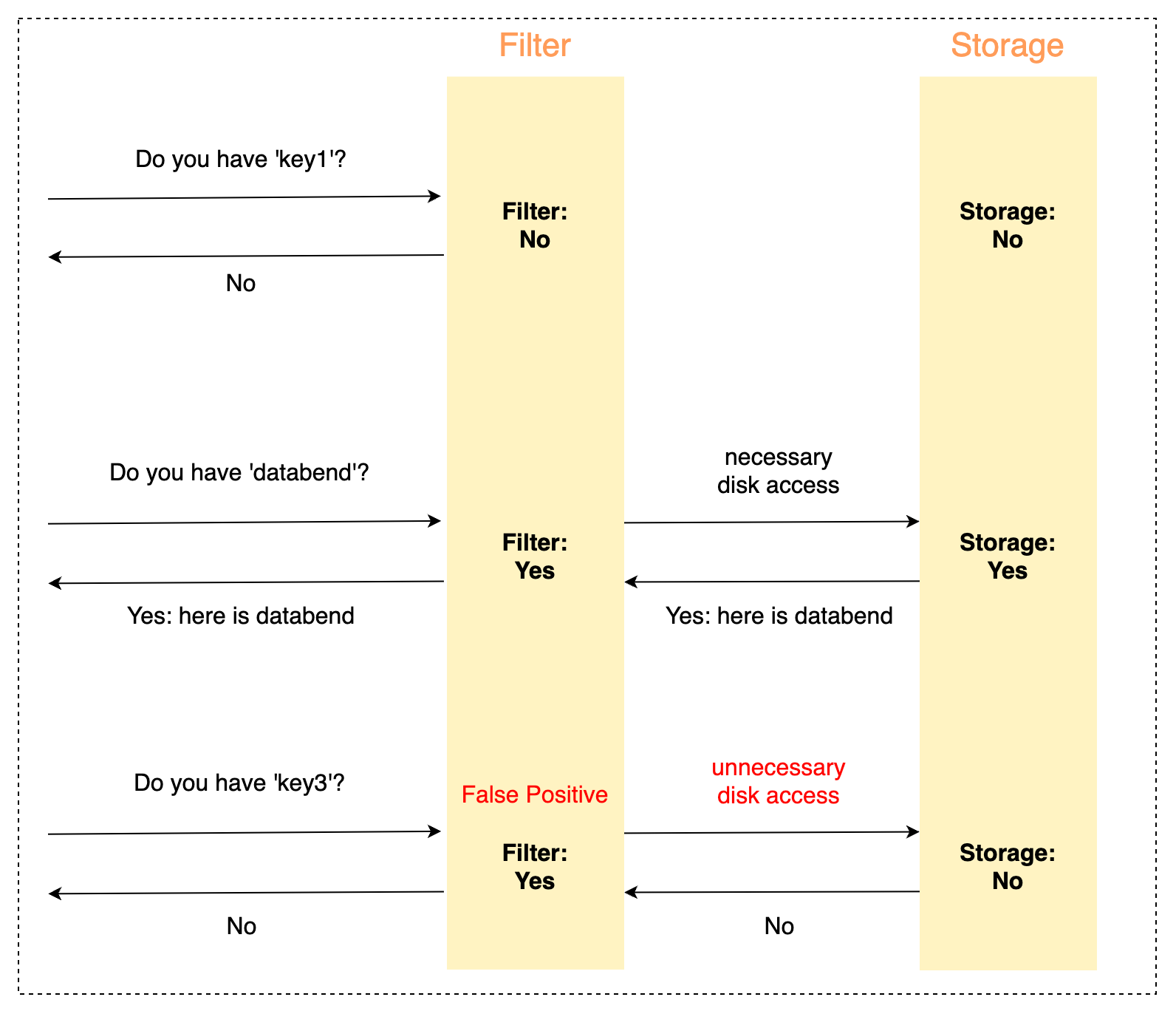
- new bloom filter that bind index with Column Id instead of column name (#10022)
What's On In Databend
Stay connected with the latest news about Databend.
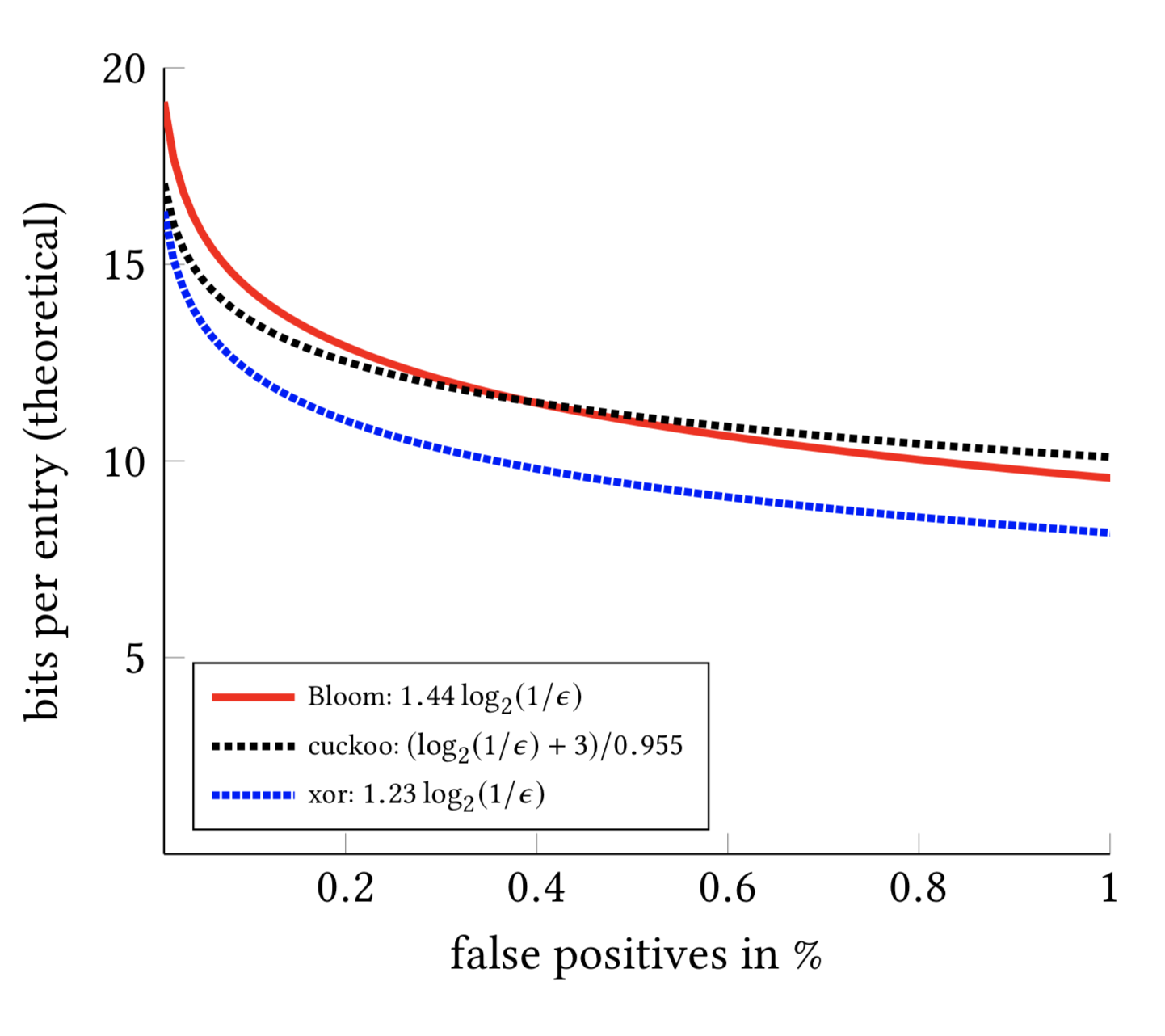
RFC: Query Result Cache
Caching the results of queries against data that doesn't update frequently can greatly reduce response time. Once cached, the result will be returned in a much shorter time if you run the query again.
How to Write a Scalar / Aggregate Function
Did you know that you can enhance the power of Databend by creating your own scalar or aggregate functions? Fortunately, it's not a difficult task!
The following guides are intended for Rust developers and Databend users who want to create their own workflows. The guides provide step-by-step instructions on how to create and register your own functions using Rust, along with code snippets and examples of various types of functions to walk you through the process.
Profile-Guided Optimization
Profile-guided optimization (PGO) is a compiler optimization technique that collects execution data during the program runtime and allows for tailoring optimizations tailored to both hot and cold code paths.
In this blog, we'll guide you through the process of optimizing Databend binary builds using PGO. We'll use Databend's SQL logic tests as an example to illustrate the step-by-step procedure.
Please note that PGO always requires generating perf data using workloads that are statistically representative. However, there's no guarantee that performance will always improve. Decide whether to use it based on your actual needs.
Learn More
What's Up Next
We're always open to cutting-edge technologies and innovative ideas. You're more than welcome to join the community and bring them to Databend.
Restructure function-related documentation
To make our documentation clearer and easier to understand, we plan to restructure our function-related documentation to follow the same format as DuckDB's documentation. This involves breaking down the task into smaller sub-tasks based on function categories, so that anyone who wants to help improve Databend's documentation can easily get involved.
Issue 10029: Tracking: re-org the functions doc
Please let us know if you're interested in contributing to this issue, or pick up a good first issue at https://link.databend.rs/i-m-feeling-lucky to get started.
Changelog
You can check the changelog of Databend Nightly for details about our latest developments.
- v0.9.39-nightly
- v0.9.38-nightly
- v0.9.37-nightly
- v0.9.36-nightly
- v0.9.35-nightly
- v0.9.34-nightly
- v0.9.33-nightly
- v0.9.32-nightly
- v0.9.31-nightly
Contributors
Thanks a lot to the contributors for their excellent work this week.
 |  |  |  |  | ![dependabot[bot]](https://avatars.githubusercontent.com/in/29110?v=4&s=117) |
|---|---|---|---|---|---|
| andylokandy | b41sh | Big-Wuu | BohuTANG | dantengsky | dependabot[bot] |
 |  |  |  |  |  |
|---|---|---|---|---|---|
| drmingdrmer | everpcpc | flaneur2020 | johnhaxx7 | leiysky | lichuang |
![mergify[bot]](https://avatars.githubusercontent.com/in/10562?v=4&s=117) |  |  |  |  |  |
|---|---|---|---|---|---|
| mergify[bot] | PsiACE | RinChanNOWWW | soyeric128 | sundy-li | TCeason |
 |  |  |  |  |  |
|---|---|---|---|---|---|
| wubx | Xuanwo | xudong963 | xxchan | youngsofun | yufan022 |
 |  |  |
|---|---|---|
| zhang2014 | ZhiHanZ | zhyass |
Connect With Us
We'd love to hear from you. Feel free to run the code and see if Databend works for you. Submit an issue with your problem if you need help.
DatafuseLabs Community is open to everyone who loves data warehouses. Please join the community and share your thoughts.
- Databend Official Website
- GitHub Discussions (Feature requests, bug reports, and contributions)
- Twitter (Stay in the know)
- Slack Channel (Chat with the community)